
Herndon, J. (Ed.) (2022). Data Science in the Library: Tools and Strategies for Supporting Data-Driven Research and Instruction. London: Facet Publishing. Książka elektroniczna dostępna w e-zasobach UW [baza: Book Collection, EBSCO]

„Dane to nowe złoto” jest zdaniem tak często wykorzystywanym, że trudno ustalić, kto wypowiedział je pierwszy. Trudno jednak się z tym zdaniem nie zgodzić, zwłaszcza w kontekście czwartego paradygmatu nauki czy tzw. przemysłu 4.0.
Chyba już nikomu nie trzeba tłumaczyć, że do zadań bibliotek akademickich na stałe weszło kuratorstwo danych oraz wspieranie społeczności uczelni w zakresie data literacy, czyli edukacji w obszarze typów tworzonych danych, ich zarządzania, przechowywania oraz udostępniania.
Książka, którą dziś omawiam przedstawia kompleksowe podejście do tematu nauki opartej na danych, uwypuklając rolę, jaką we wspieraniu tej nauki odgrywają właśnie biblioteki i kreśląc dla nich wskazówki dalszych działań. Skoro jedną z misją jest wzmacnianie (ang. empowerment) społeczeństwa, to w kontekście tej książki chodzi o wzmocnienie kompetencji związanych z danymi (ang. data literacy). Zaproponowanie nowych usług, podniesienie świadomości użytkowników na temat pozyskiwania, zarządzania i archiwizowania danych – wszystko to, aby ułatwić użytkownikom funkcjonowanie w data science community.
Książka zbudowana jest z czterech części, podzielona na osiem rozdziałów:
- Cz. 1 – Data Science and Research Libraries – Perspectives (rozdz. 1 – 2)
- Cz. 2 – Data Science Instruction (rozdz. 3 – 4)
- Cz. 3 – Data Science Services (rozdz. 5 – 6)
- Cz. 4 – Designing and Staffing Data Science (rozdz. 7 – 8)
Warto zacząć od definicji terminu data science, czyli nauki opartej na danych. Jak słusznie zauważa we wstępie redaktorka tomu, łatwiej zdefiniować ją, pokazując przykłady wdrożeń niż podejście teoretyczne. W kontekście akademickim nauka oparta na danych zakłada wykorzystanie wielu metod, np. uczenia maszynowego (ang. machine learning), analizy mediów społecznościowych, analizy danych przestrzennych (ang. spatial analysis), analizy tekstu, czy analityki internetowej (ang. web analytics).
Wyzwaniem, a zarazem zauważalnym trendem na uczelniach jest stworzenie oferty usług, która kompleksowo wspierałaby naukę opartą na danych. Biblioteka samotnie (czy samodzielnie, jak to się teraz zwykło mówić) wiele nie zdziała, głównie ze względu na brak kadry informatyczno-analitycznej. Ale już wespół w zespół wspracie dla uczelnianej społeczności można wzmóc.
I właśnie takie odnoszące sukces uczelniane alianse opisuje ta książka, przynosząc pewną inspirację i pokazując ścieżki, które warto przetrzeć w poszukiwaniu najlepszych rozwiązań. Na pewno należy zapomnieć o tradycyjnej, instytucjonalnej strukturze. Jednostki wspomagające data science są tzw. cross-departamental – międzywydziałowe, międzyjednostkowe. To zespoły budowane na bazie kompetencji poszczególnych ich członków, a nie na bazie afiliacji. Trudne, zwłaszcza tam, gdzie administracja nadal pojmowana jest jako: gabinet, osiem godzin pracy w uregulowanych godzinach, rejestracja czasu pracy, przynależność do konkretnych jednostek, hierarchiczna struktura zarządzania. Ale tak właśnie powinno to wyglądać – zespół dobrze wykwalifikowanych edukatorów. Ze strony bibliotek – specjaliści od wspierania tworzenia planu zarządzania danymi, praw autorskich, kompetencji informacyjnych. Ze strony jednostek informatycznych – specjaliści od kodowania, przetwarzania danych, obsługi oprogramowania do analizy danych. Tych drugich nie warto zatrudniać w bibliotece. Warto poza bibliotekę wyjść i zaprosić ich do współpracy.
Przykłady takiej udanej współpracy znalazły się w drugiej części książki, poświęconej edukacji studentów.
W rozdziale trzecim opisano prace bibliotekarek i bibliotekarzy z Uniwersytetu Kalifornijskiego w Berkeley (Cal) w zakresie ponownego wykorzystania danych badawczych, na przykładzie Berkeley Research Data Management Program – wspólnej inicjatywy biblioteki Cal i działu Research IT. Współpraca ta zaowocowała m.in. opracowaniem przedmiotu pn. Open Science and Reproducibility, włączonego do oferty dydaktycznej Cal, skierowanego do studentów kierunku Data Science. To połączenie wiedzy dotyczącej data literacy – kompetencji w zakresie danych badawczych (wykorzystanie katalogów bibliotecznych, zagadnienia dot. FAIR data, repozytoria danych) z konkretną wiedzą informatyczną, dotyczącą programów takich jak Python czy R czy pisania kodów.
Z kolei w rozdziale czwartym czytamy o przedmiocie pn. Introduction to Data Science and Statistical Thinking, którego program został opracowany na Duke University w Północnej Karolinie w 2014 r., i który od 2019 r. pn. Introduction to Data Science jest oferowany studentom także na Uniwersytecie w Edynburgu. W sylabusie ostatniego, w części dotyczącej oczekiwanym efektom kształcenia, czytamy, że student nauczy się:
- wykorzystać wszystkie etapy analizy danych, w tym: importowanie, porządkowanie, przekształcanie, wizualizację, modelowanie i komunikację
- krytykować twierdzenia oparte na danych i oceniać decyzje oparte na danych
- interpretować wyniki poprawnie, skutecznie i kontekstowo, bez polegania na żargonie statystycznym
- ukończyć projekt badawczy na wybranym przez siebie zbiorze danych, demonstrując opanowanie analizy danych
- używać języka obliczeń statystycznych R, aby wykonać w pełni odtwarzalne analizy danych.
Czyli konkretne umiejętności praktyczne, przydatne nie tylko w trakcie studiów, ale także w pracy zawodowej, coraz częściej wykorzystującej analizy danych do przygotowywania różnorakich raportów, sprawozdań itp.
Na wykresie zaproponowanym przez Mine Çentinkaya-Rundel, autorkę rozdziału, trzy najważniejsze filary przedmiotu wyglądają jak poniżej.
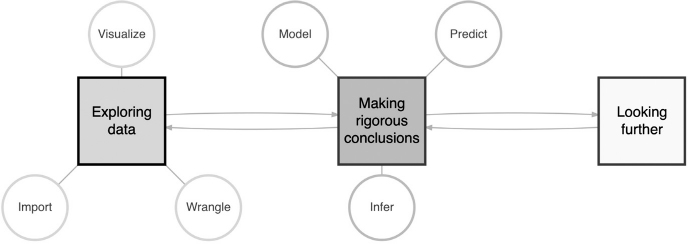
Trzecia część książki poświęcona jest wspieraniu badań pracowników naukowych. W rozdziale piątym opisano inicjatywy na Uniwersytecie Waszyngtońskim. Aby lepiej wspierać badaczy, otwarto tam Washington Research Foundation (WRF) Data Science Studio – otwartą przestrzeń (nie bez znaczenia, że na ostatnim piętrze wysokiego budynku na campusie, co daje widok na panoramę Seattle), gdzie codziennie można przyjść na indywidualne konsultacje, szkolenia czy warsztaty dotyczące pracy z danymi.
Data Science Studio nie zmieniło znacznie pracy biblioteki uniwersyteckiej – wręcz przeciwnie: ta także poszerzyła swoją ofertę wsparcia badaczy w zakresie pracy z danymi. Jednak o ile Studio skupia się na aspektach informatycznego przetwarzania danych, o tyle biblioteka wzmocniła swoją działalność w dziedzinie najlepiej już rozpoznanej – otwartej nauki, pozyskiwaniu danych, planie zarządzania danymi, organizacji, przechowywaniu, ponownym wykorzystaniu danych, cytowaniu i dzieleniu się danymi, zarządzania repozytorium. Powstał zespół usług ds. danych, który z jednej strony zajął się wsparciem istniejących już projektów badawczych, a z drugiej opracował ofertę edukacyjną dla tych badaczy, którzy chcieliby dowiedzieć się, jak pracować z danymi. Zawiera ona zarówno rozbudowane przewodniki dostępne na stronie WWW biblioteki, jak i warsztaty czy indywidualne konsultacje.
Rozdział szósty to powrót na Uniwersytet Kalifornijski, tym razem na jego kampus w Los Angeles (UCLA). Opisano ciekawą ewolucję analogowego archiwum nauk społecznych (istniejącego na uniwersytecie od lat 70. XX w.), które z czasem przekształciło się w międzydyscyplinarne centrum wspierania nauki opartej na danych, służące społeczności badawczej UCLA. Zmianę wymogła technologia i sami badacze, którym potrzebne były nowsze, bardziej zaawansowane umiejętności pracy z danymi, zakładające np.: wykorzystanie języka R, programu Python czy OpenRefine do analizy danych. Potrzebne było też profesjonalne kuratorstwo nad danymi audiowizualnymi, nie tylko tekstowymi. I tak w 2014 r. archiwum nauk społecznych włączono w strukturę biblioteki, zasilając kadrę biblioteczną pracownikami płynnie poruszającymi się w badaniach, danych, ich analizie. Następnie, w wyniku tych przekształceń powstało Data Science Center – część biblioteki, która oferuje społeczności uniwersyteckiej pogłębianie kompetencji związanych z danymi (ang. data literacy), kodowaniem, planowaniem zarządzania danymi badawczymi, pozyskiwaniem danych, organizacją, przechowywaniem czy ich ponownym wykorzystaniem.
I tak przechodzimy do czwartej części książki, która poświęcona jest kadrze. Kim jest bibliotekarz rozumiejący dane (ang. data savvy librarian)? Jaką wiedzę, wykształcenie, umiejętności powinien posiadać i jak je rozwijać? W rozdziale siódmym Jeanette Ekstrøm z Biblioteki Duńskiego Uniwersytetu Technicznego pisze, że powinna to być osoba, która dokładnie wie, jak wygląda cykl badawczy w środowisku akademickim, które wspiera. Wtedy zna narzędzia i odpowiedzi na trudne pytania. Zna specyfikę wytwarzanych danych oraz ich formaty. Moim zdaniem najlepiej zatem, aby była to osoba, która sama prowadziła badania, np. przygotowując doktorat. To rzeczywiście poszerza perspektywę. Zresztą nie tylko badawczą.
Ten rozdział poświęcony jest też samodoszkatłcanu. Parafrazując Prezydenta Andrzeja Dudę, trzeba pracować cały czas, cały czas się czegoś uczyć, bez przerwy.
Ciekawe przykłady przychodzą z Danii. Tamtejsi bibliotekarze stowarzyszyli się w Data Savvy Network i kształcą się nawzajem. Zarówno podczas jedno- czy półdniowych warsztatów, jak i w trakcie krótkich setów dydaktycznych w czasie pracy – to pomysł szwedzki, z Upsali, program „15 Minutes of Data”. To jest moje marzenie – żebyśmy raz w tygodniu odrywali się od rutynowej pracy i spotykali na odświeżających spotkaniach poświęconych najnowszym bibliotecznym hot topics, niekoniecznie związanym tylko z nauką opartą na danych.
Rozdział ósmy to podsumowanie całej książki. Uwypukla potrzebę partnerstwa między jednostkami na uczelniach, które, jak pokazuje publikacja, może być bardzo owocne i dawać same korzyści społeczności akademickiej. Rysuje zadania dla tzw. jednostek IT – to już nie tylko podtrzymywanie uczelnianej infrastruktury informatycznej, ale także szkolenia użytkowników. Zwraca wreszcie uwagę na potrzebę zrównoważonego rozwoju i myślenia w perspektywie długoterminowej. Finansowanie wszystkiego z projektów to bolączka naszych czasów. Projekt się kończy = finansowanie się kończy = podtrzymywanie usługi czy infrastruktury się kończy. Ślepa uliczka w kontekście wspierania nauki. A kadra nie może tak bardzo rotować, zespół powinien umacniać się, nabierając doświadczenia. I wzmacniając swój wizerunek wśród społeczności. Rozpoznawalność i promocja to też ważna kwestia poruszona w podsumowaniu – co z tego, że zaoferujemy fajerwerki, jeśli mało kto o nich wie? Eventy, współpraca z wydziałami, pokazywanie wartości usług biblioteki na forum uczelni. Tym też należy się zająć.
Niejako na marginesie książki chciałabym jeszcze zwrócić uwagę na nazwę dość często się w niej przewijającą, zwłaszcza w kontekście dokształcania się. Library Carpentry. Biblioteczni stolarze, platforma poświęcona wzmacnianiu bibliotecznych umiejętności pracy z oprogramowaniem i danymi. Samozwańcza inicjatywa międzynarodowa, oferująca warsztaty, przewodniki, bloga, listę mailingową. Warto śledzić!
Zuza Wiorogórska, Pełnomocniczka ds. edukacji informacyjnej i komunikacji naukowej
