
Crowdsourcing to jedno z tych pojęć, które nie doczekały się jeszcze polskiego odpowiednika, ani nawet jasno sprecyzowanej definicji. Jedna z bardziej trafnych mówi, że jest to wykorzystanie mądrości i potencjału społeczności do celów własnych jednostki, organizacji lub dla dobra ogółu.[1] Brzmi to bardzo mądrze, jednak czym właściwie jest crowdsourcing i jakie może mieć zastosowanie w projektach transkrypcyjnych?
Wyobraźmy sobie bibliotekę, dla lepszego zobrazowania przykładu niech to będzie BUW, której zbiory specjalne w 2020 roku liczyły ponad 400 tysięcy jednostek. Zastanówmy się teraz, czego moglibyśmy dowiedzieć się, mając możliwość przeszukiwania zapisów myśli artystów, naukowców, wynalazców i odkrywców, zawartych w dokumentach znajdujących się w zbiorach specjalnych Biblioteki? Dotychczas zeskanowano i udostępniono zaledwie niewielki ich fragment, jeszcze mniej zostało opracowanych w sposób naukowy, a następnie wydanych. Dzięki digitalizacji i transkrypcji każdy może pomóc w wydobyciu przemyśleń i wizji ich twórców na światło dzienne.
Cele crowdsourcingu w projektach transkrypcyjnych są dwojakie: po pierwsze otrzymujemy możliwość tworzenia czytelnych i łatwych do przeszukiwania kopii dokumentów rękopiśmiennych. W przypadku materiałów drukowanych zawsze można posłużyć się programem do OCR-u. Istnieją wprawdzie aplikacje do automatycznego odczytywania pisma ręcznego, jednak ich obsługa to proces żmudny i długotrwały, dlatego transkrypcja wydaje się w takich przypadkach najlepszym rozwiązaniem. Po drugie – i co najważniejsze – tego rodzaju projekty mogą być sposobem na zaangażowanie szerszej społeczności w badania naukowe.
Właściwie każdy zainteresowany może zalogować się na internetowej stronie wybranego projektu, odszukać, przeczytać, a następnie przepisać udostępnione online dokumenty. Zachęcanie do korzystania z oryginalnych źródeł to ogromna szansa na uzyskanie wielu zróżnicowanych perspektyw badawczych. Taka też jest idea społecznej transkrypcji tekstów. W swoim najpełniejszym znaczeniu crowdsourcing nie polega bowiem na tym, by ktoś wykonał pracę za autorów projektu czy portalu, ale na zaoferowaniu użytkownikom możliwości uczestniczenia w tworzeniu społecznej tożsamości.
***
W czasach pandemii koronawirusa, muzea, archiwa i biblioteki naukowe na całym świecie odnotowują ogromne zainteresowanie prowadzonymi przez siebie projektami transkrypcyjnymi. Utraciwszy dostęp do tak wielu podstawowych elementów życia codziennego, cyfrowi stenografowie zaczęli coraz chętniej sięgać po dokumentację historyczną, aby twórczo wykorzystać czas kwarantanny, przy okazji dbając też o swoją psychikę. Na wielu uczelniach prowadzący zajęcia, szukając ciekawych pomysłów nauczania na odległość, z powodzeniem namawiali swoich uczniów do udziału w tych projektach, gdyż oprócz nauki o wydarzeniach i postaciach historycznych, mieli też okazję pogłębiać również wiedzę z paleografii, kaligrafii oraz innych nauk pomocniczych historii.
Biblioteka Kongresu w Waszyngtonie od połowy marca ubiegłego roku odnotowała pięciokrotny wzrost liczby nowych kont na swojej platformie transkrypcyjnej.[2] W Smithsonian Institution liczba nowych użytkowników wzrosła z około 200 miesięcznie w czasach sprzed pandemii, do ponad 5000 miesięcznie obecnie.[3] Aby sprostać niezaspokojonemu popytowi, instytucje naukowe starają się jak mogą digitalizować i udostępniać kolejne partie dokumentów do przepisywania.
Historia zawsze pozostanie fascynującą opowieścią, dlatego każdy znajdzie w niej coś dla siebie. Dzienniki sufrażystek, wiersze Walta Whitmana, listy czarnoskórych niewolników, dokumenty angielskiego filozofa Jeremy’ego Benthama, jadłospisy z czasów Wielkiego Kryzysu, dzienniki wielorybników, fanziny science-fiction, roczniki szkolne… Albo akta korporacji Maidenform, pionierskiego producenta biustonoszy:
Kampanie reklamowe Maidenform odniosły ogromny sukces i wzbudziły zarówno kontrowersje, jak też pochwały – czytamy na stronie Smithsonian. Pomóż przepisać niektóre z historycznych dokumentów firmy, w tym reklamy i raporty, aby dowiedzieć się więcej o historii przemysłu biustonoszy i kampaniach marketingowych kierowanych do kobiet.[4]

Reklama prasowa Maidenform z 1955 roku. Źródło: Wikimedia Commons
Z perspektywy badawczej, transkrypcja zapisów historycznych okazała się tanim i efektywnym rozwiązaniem dla instytucji badawczych, aby ich ogromne zbiory dokumentów były dostępne do przeszukiwania online dla naukowców oraz innych osób zainteresowanych badaniami historycznymi. Materiały są udostępniane online, ochotnicy przepisują ich treść, a następnie przesyłają teksty do korektorów, którzy je sprawdzają, poprawiają i publikują w sieci.
Przed pandemią wolontariuszami byli głównie emeryci, cierpliwie i powoli wykonujący najbardziej wymagające i czasochłonne zadania. Teraz, gdy dostęp do wielu archiwów i bibliotek wciąż jest utrudniony, szeregi młodych wolontariuszy rosną, a ich wkład pracy jest ogromny. Mają do wyboru liczne projekty transkrypcyjne, które mogą zaspokoić zainteresowania i gusta najwybredniejszych.
***
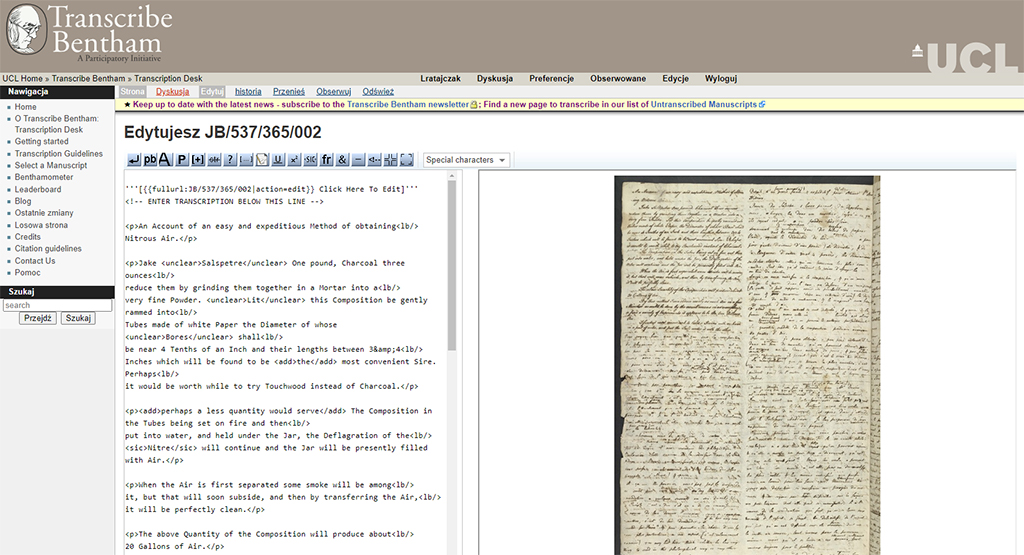
Project Bentham
University College London: Project Bentham
https://transcribe-bentham.ucl.ac.uk/td/
Jednym z najstarszych i najpopularniejszych jest projekt Transcribe Bentham, realizowany przez University College London. Celem projektu jest opracowanie rękopisów Jeremy’ego Benthama, zgromadzonych i udostępnianych przez archiwum Kolegium Uniwersyteckiego w Londynie. UCL przechowuje 60 tysięcy kart rękopisów autorstwa angielskiego filozofa, jednak tylko niewielka część tego zasobu jest dziś opisana i przepisana. Sposobem na zintensyfikowanie prac nad archiwum Benthama miało być otwarcie się na aktywność wolontariuszy działających online, co nastąpiło w 2010 roku i z powodzeniem trwa nadal.
Osią projektu jest specjalnie przygotowany serwis Wiki, gdzie udostępnione zostały podstawowe informacje związane z metodologią transkrypcji oraz skany do opracowania. W tym przypadku transkrypcja nie polega na prostym przepisaniu tekstu, ale opracowaniu jego cyfrowej wersji za pomocą znaczników TEI. W największym uproszczeniu jest to odpowiednio zdefiniowana składnia znaczników w schemacie XML, która pozwala na bardzo dokładne oddanie wszystkich właściwości dokumentu.
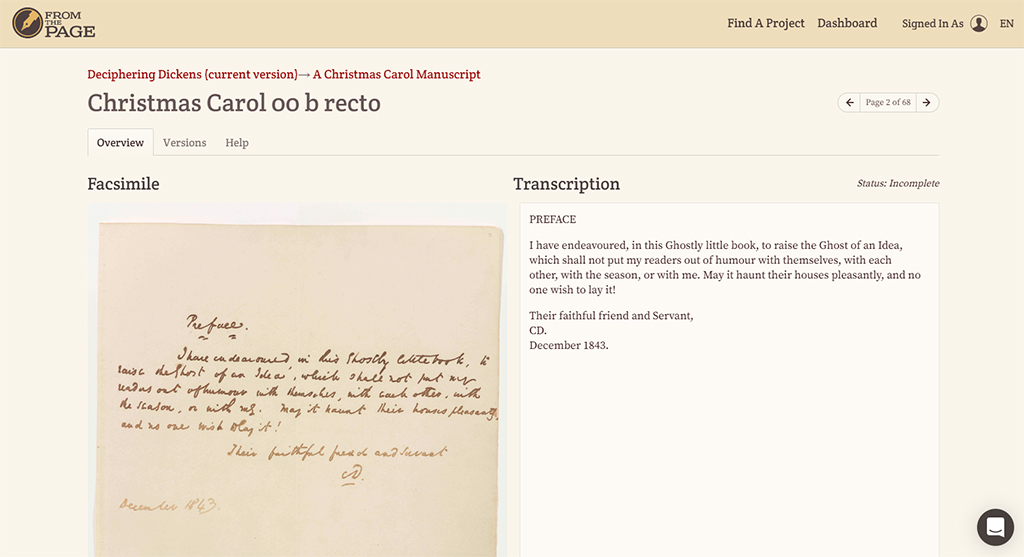
From the Page
From the Page
https://fromthepage.com/
Kolejnym ciekawym przedsięwzięciem jest platforma From the Page, która powstała w 2005 roku jako prywatna inicjatywa pewnego amerykańskiego małżeństwa, które chcąc lepiej poznać historię swojej rodziny zaprojektowało stronę internetową, na której przyjaciele i znajomi mogli uczestniczyć w przepisywaniu rodzinnych pamiętników. Dziś jest to duże, międzynarodowe przedsięwzięcie, w ramach którego swoje projekty transkrypcyjne prowadzą biblioteki, uniwersytety i muzea. Serwis zapewnia zaplecze techniczne oraz serwery. Za miesięczną opłatą można w jego ramach tworzyć dowolne projekty transkrypcyjne, realizowane przez wolontariuszy.
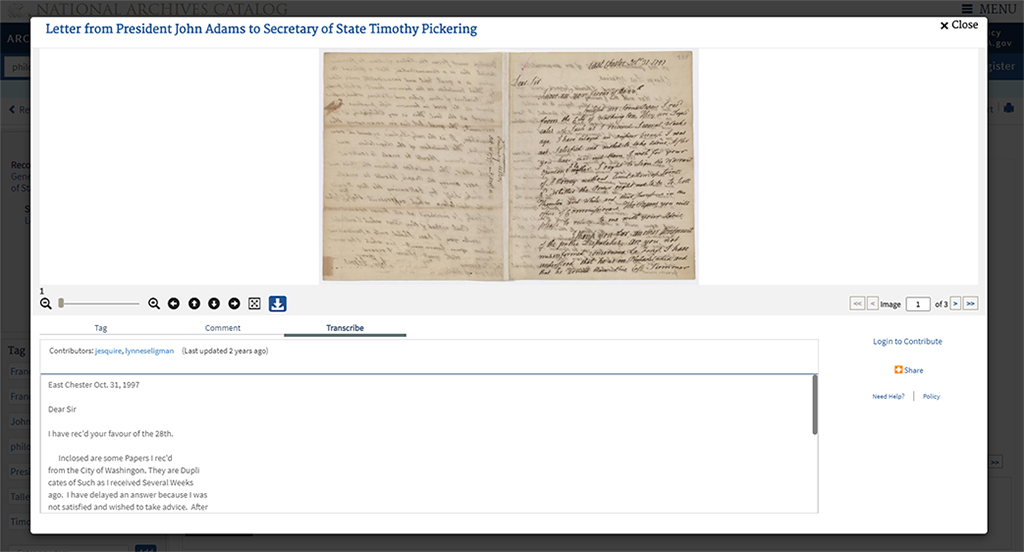
Citizen Archivist
National Archives: Citizen Archivist
https://www.archives.gov/citizen-archivist
Obywatelscy archiwiści to z kolei projekt Amerykańskiego Archiwum Narodowego, które w 2010 roku uruchomiło specjalny serwis internetowy, za pomocą którego wolontariusze z całego świata biorą udział w przepisywaniu zeskanowanych zbiorów rękopiśmiennych, liczących ponad 2 miliony stron. Wśród przykładowych inicjatyw można tu wymienić angażowanie wolontariuszy do tagowania i przepisywania dokumentów, tworzenia napisów do filmów historycznych, redagowania artykułów Wiki oraz indeksowania obserwacji pogodowych z dzienników okrętowych. Wolontariusze pomagają dotrzeć do informacji zawartych w cyfrowych skanach dokumentów historycznych. Opisują dokumenty słowami kluczowymi, co jest prostym i atrakcyjnym sposobem na uczynienie ich bardziej dostępnymi.
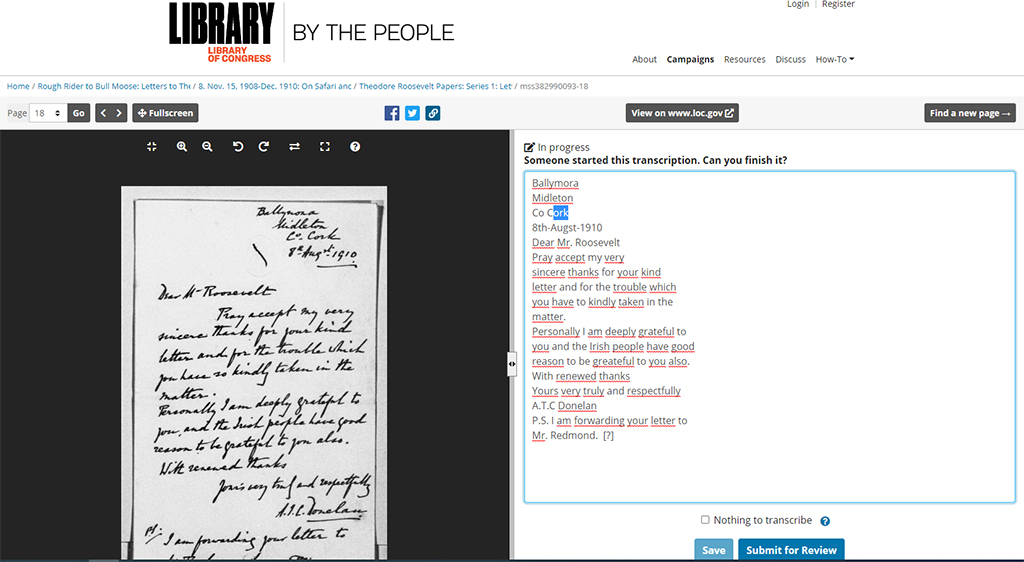
By the People
Library of Congress: By the People
https://crowd.loc.gov/
By the People zaprasza zainteresowanych wolontariuszy do transkrypcji zdigitalizowanych kopii prywatnych listów, pamiętników, rachunków, przemówień i innych dokumentów, pozostawionych przez mniej lub bardziej sławnych ludzi, którzy byli zaangażowani w różne ruchy dziejowe, głównie w XIX i na początku XX wieku. Uruchomiona jesienią 2018 roku, By the People pogrupowała swoje dokumenty w różne „kampanie”, takie jak na przykład wojna secesyjna, ruch abolicjonistyczny, czy ruch sufrażystek – tak, aby użytkownik mógł łatwo wybrać tematykę, która najbardziej go interesuje. Można więc samodzielnie dokonać transkrypcji, sprawdzić czyjąś pracę, lub po prostu czytać.
Project PHaEDRA
Smithsonian Digital Volunteers: Project PHaEDRA
https://transcription.si.edu/project/29304
Na przełomie XIX i XX wieku dziesiątki kobiet pracujących na Harvardzie zgromadziły się, by wspólnie obserwować niebo. Znane zazwyczaj jako Harwardzkie Komputery,[5] zajmowały się porównywaniem, klasyfikowaniem i katalogowaniem obiektów na niebie, głównie na podstawie fotografii. Niektóre z nich, w tym Annie Jump Cannon, która odkryła kilka nowych gwiazd i opracowała nowy system ich klasyfikacji, zyskały pewien zasłużony rozgłos. Jednak wiele z ich prac zostało przyćmionych przez większy projekt, przeprowadzony w Obserwatorium Harvarda i sławę Edwarda Charlesa Pickeringa, który nim kierował.
Teraz Biblioteka Wolbacha przy Harvard-Smithsonian Center for Astrophysics zachęca do pomocy w nowym przedsięwzięciu, nazwanym Projekt PHaEDRA (lub Preserving Harvard’s Early Data and Research in Astronomy). Jednym z etapów projektu jest przepisywanie treści notatników kilku wspomnianych wyżej kobiet. W części poświęconej notatkom o gwiazdach uczestnicy proszeni są o cyfrowe przeglądanie tych zapisków w poszukiwaniu numerów zdjęć, które pozwolą dopasować notatki do odpowiednich fotografii, nad którymi pracowały badaczki.
Building Inspector
The New York Public Library: Building Inspector
http://buildinginspector.nypl.org/
Oprócz cieszącego się największą popularnością projektu Nowojorskiej Biblioteki Publicznej What’s on the Menu, w ramach którego przepisywane są historyczne karty dań restauracji, biblioteka oferuje jeszcze wiele innych projektów, które potrzebują pomocy chętnych wolontariuszy, w tym Building Inspector. Projekt ten angażuje osoby zainteresowane kartografią i historią lokalną do odkrywania przeszłości Nowego Jorku poprzez identyfikację budynków i innych punktów orientacyjnych na starych planach miasta. Komputery wykonują co prawda większość operacji rozpoznawczych, jednak ludzie pomagają sprawdzić ich pracę, sugerują również, co należałoby dodać do zgromadzonych już informacji. Biblioteka NYPL ma nadzieję wykorzystać ten projekt do przekształcenia swoich historycznych atlasów w swoiste wehikuły czasu.
Ships’ Logs Collection
Nantucket Historical Association Transcription Initiative: Ships’ Logs Collection
https://fromthepage.com/nharl
Nantucket było niegdyś tętniącym życiem centrum amerykańskiego przemysłu wielorybniczego. I choć tamtejsi harpunnicy nie przemierzają już wzburzonych wód w pogoni za cenną zdobyczą, pozostawili po sobie imponującą spuściznę pisarską. Niestety, dzienniki, w których zapisywano codzienne życie na pokładzie statków, są często spisane bardzo trudnym do odczytania ręcznym pismem. Od października 2019 roku Stowarzyszenie Historyczne Nantucket pracuje nad digitalizacją i transkrypcją swojej kolekcji ponad 400 dzienników pokładowych, w tym 11 prowadzonych przez kobiety żeglujące po morzu. Wiele z dzienników jest ilustrowanych i zawiera wiersze oraz osobiste anegdoty – mówi Sara David, archiwistka do spraw digitalizacji w bibliotece Nantucket Historical Association. Niektóre z nich czyta się tak, jakby to był drugi „Moby Dick.” [6]
***
Dokumenty rękopiśmienne są coraz częściej digitalizowane i udostępniane do naukowej analizy oraz różnorakich badań. W tym celu opracowano wiele specjalistycznych narzędzi komputerowych, które wspierają pracę wolontariuszy na całym świecie, zaangażowanych w setki projektów transkrypcyjnych. Mimo tego, że przez ostatnie lata pojawiło się i rozwinęło wiele nowych inicjatyw, a wraz z nimi nastąpiła wyraźna specjalizacja wiedzy związanej z transkrypcją tekstów, nie ulega wątpliwości, że jeszcze wiele zostało do zrobienia i udoskonalenia.
Większość narzędzi transkrypcyjnych działa w oparciu o strony internetowe, które nie wydają się odpowiednim miejscem do pracy z dokumentami zawierającymi tzw. dane wrażliwe, ponieważ zawsze istnieje ryzyko ujawnienia takich informacji osobom niepowołanym. Zautomatyzowane metody optycznego rozpoznawania znaków (OCR) wciąż nie najlepiej radzą sobie z pismem ręcznym, ze względu na szereg różnych czynników, takich jak duża zmienność charakteru pisma, stopień zniszczenia dokumentów papierowych oraz błędy popełnione podczas ich digitalizacji. Dodatkowo ręczne przepisywanie tekstów wciąż jest procesem powolnym i mimo wszystko generującym pewne koszty. Rozpoznawanie i analiza pisma ręcznego wciąż więc pozostają aktywnym obszarem badań.
Wydaje się, że przyszłość projektów transkrypcyjnych leży w prowadzonych obecnie badaniach nad sieciami neuronowymi oraz tzw. deep learning, czyli procesem, w którym komputer uczy się wykonywania zadań naturalnych dla ludzkiego mózgu, takich jak rozpoznawanie mowy, przetwarzanie języka naturalnego lub identyfikowanie obrazów. Zamiast żmudnego zbierania, analizowania i przetwarzania danych, komputer, dysponując jedynie podstawowymi parametrami analizowanego zagadnienia, przygotowuje się do samodzielnego uczenia i precyzowania osiągniętych wniosków. Dotychczasowe badania nad deep learning osiągnęły bezprecedensowe wyniki w takich dziedzinach jak rozpoznawanie oraz wyszukiwanie słów i znaków.[7] Pomimo tego, że obecny stan wiedzy i wykorzystywane metody nie są jeszcze wystarczająco skuteczne, to jednak kwestią czasu jest zautomatyzowanie procesu transkrypcji pisma ręcznego.
Póki co jednak wszelkiego rodzaju obywatelskie projekty naukowe pozostają niezwykle ważnymi obszarami zaangażowania i wspierania otwartej przestrzeni intelektualnej oraz współpracy różnych środowisk. Pomagają zatrzeć różnicę pomiędzy badaczem nauk humanistycznych, a jego odbiorcą, pozwalając zwykłemu miłośnikowi historii i studentowi znacznie bardziej zaangażować się w badania naukowe. Nawet jeśli COVID-19 powoduje dystans społeczny w świecie rzeczywistym, wciąż jeszcze istnieje cyfrowa przestrzeń do uczenia się, nauczania i wspólnej pracy. Oczywiście do czasu, kiedy zastąpi nas sztuczna inteligencja…
Łukasz Ratajczak (Gabinet Rękopisów BUW)
Bibliografia:
Blickhan, S.; Krawczyk, C. Individual vs. Collaborative Methods of Crowdsourced Transcription. HAL Archives-Ouvertes, 3.12.2019
https://jdmdh.episciences.org/5759/pdf
Davies, R. Crowdsourcing in cultural heritage. Final Report
https://pro.europeana.eu/files/Europeana_Professional/Projectpartner/EuropeanaCommonCultureProjectFiles/Crowdsourcing%20study%20report.pdf
Hakkarainen, J-P. From crowdsourcing to nichesourcing. The National Library of Finland Bulletin.
https://blogs.helsinki.fi/natlibfi-bulletin/?page_id=206
Krok, E. Crowdsourcing w biznesie. Marketing i Rynek/ Journal of Marketing and Market Studies, T. XXVI, nr 11 (2019), s. 75
Lombardi, F. Deep Learning for Historical Document Analysis and Recognition – A Survey. Journal of Imaging, Vol. 6(10), no. 110 (2020)
Rachwalska von Rejchwald, J. La «huitième saison» de la traduction. Studia Romanica Posnaniensia T. 45, nr 4 (2018), s.61-74
Severson, S. Crowding the Library: How and why Libraries are using Crowdsourcing to engage the Public. Innovations in Practice, Vol. 14, no. 1 (2019)
Netografia:
https://blogs.loc.gov/loc/2018/10/explore-transcribe-and-tag-at-crowd-loc-gov/
https://content.fromthepage.com/sara-david/
https://pl.wikipedia.org/wiki/Harwardzkie_komputery
https://transcription.si.edu/news
https://transcription.si.edu/project/23298
Przypisy:
[1] Krok, E. Crowdsourcing w biznesie. Marketing i Rynek/ Journal of Marketing and Market Studies, T. XXVI, nr 11 (2019), s. 75
[2] https://blogs.loc.gov/loc/2018/10/explore-transcribe-and-tag-at-crowd-loc-gov/
[3] https://transcription.si.edu/news
[4] https://transcription.si.edu/project/23298
[5] https://pl.wikipedia.org/wiki/Harwardzkie_komputery
[6] https://content.fromthepage.com/sara-david/
[7] Lombardi, F. Deep Learning for Historical Document Analysis and Recognition – A Survey. Journal of Imaging, Vol. 6(10), no 110 (2020)