
OCR to skrót od angielskiej frazy Optical Character Recognition. Tłumacząc na język polski jest to optyczne rozpoznawanie znaków. Z tym skrótem należy powiązać zestaw programów lub silników programistycznych służących do rozpoznawania znaków lub całych tekstów z plików graficznych w postaci rastrowej. Do najlepszych i najbardziej popularnych należą tutaj: Abby Fine Reader i Tesseract. Rozpoznawanie znaków w dużym stopniu jest powiązane z zagadnieniem rozpoznawania wzorców, co z kolei wiąże się z tematem sztucznej inteligencji (AI). Można zaryzykować stwierdzenie, że zanim AI stała się bardzo popularnym tematem, ktoś kto miał do czynienia z OCR miał już z nią styczność. Oczywiście jest to stwierdzenie mocno na wyrost, ponieważ zanim zaczęto mówić o sztucznej inteligencji istniał temat sieci neuronowych, które pozwalały programom uczyć się pewnych wzorców. AI to, mimo wszystko, coś więcej niż tylko sieci neuronowe, chociaż z nich z pewnością korzysta.

Obrazek Pixabay
Jak to działa?
Programy do rozpoznawania OCR wykorzystują różne metody segmentacji obrazu, np. progowanie w celu wyodrębnienia poszczególnych znaków z obrazu, które są klasyfikowane jako poszczególne litery. Segmentacja obrazu polega na podziale obrazu na obszary będące zbiorami pikseli (punktów), które są jednorodne pod względem pewnych wybranych własności. Jako kryteria jednorodności obrazu wybierane są często takie właściwości jak poziom szarości, barwa, czy tekstura oryginalnego obiektu, która wpływa na jakość uzyskanej kopii cyfrowej. Progowanie to metoda uzyskiwania obrazu binarnego na podstawie obrazu kolorowego lub w odcieniach szarości. Programy do rozpoznawania OCR najczęściej, aby wyeliminować pomyłki, sprawdzają całość rozpoznawanego przez nie tekstu lub poszczególne wyrazy pod kątem poprawności ortograficznej i gramatycznej danego języka.
Technologia OCR znajduje szerokie zastosowanie zarówno w firmach, urzędach, jak i w bibliotekach. Rejestrowanie dokumentów oraz ich archiwizacja to jedne z podstawowych jej zadań w stosunku do dokumentów elektronicznych oraz tych oryginalnie występujących w formie papierowej, które trzeba przechowywać w formie cyfrowej. W tym przypadku skuteczność uzyskania bardzo dobrego OCR-u waha się na poziomie od 99% do 99.5%.
Zupełnie inaczej ma się sytuacja w przypadku bibliotek. Archiwizowane zbiory biblioteczne są najczęściej różnej jakości. Książki na przestrzeni wieków były drukowane różną czcionką, na różnej jakości papierze, zmieniała się gramatyka i ortografia danego języka itd. Tutaj jakość OCR zależy od bardzo wielu czynników i nie jest ona zawsze taka oczywista. W bibliotekach OCR jest wykorzystywany przede wszystkim do prezentowania zbiorów szerszemu gronu czytelników za pomocą dokumentów elektronicznych.
Największe przeszkody w OCR-owaniu dokumentów
Jeśli chodzi o dokumenty born-digital czyli takie, które powstały w formie cyfrowej, nie należy się tu spodziewać zbyt wielu problemów związanych z procesem OCR. Nieco inaczej ma się sprawa z dokumentami – plikami graficznymi, powstałymi w procesie skanowania.
Najczęstszym problemem związanym z uzyskaniem dobrego OCR-u jest słaba jakość druku źródłowego. Jeśli gęstość pikseli jest zbyt mała (lub zbyt duża), programy zaczynają się gubić dając nieprawidłowe wyniki lub w ogóle nie rozpoznając znaków lub słów.
Drugim problemem, który może się pojawić jest brak jednolitości tekstu. Użycie w tekście różnych krojów oraz wielkości czcionek wpływa ujemnie na proces OCR.
Zbyt wyblakłe kolory i za mały kontrast oraz użycie innego koloru niż czarny w przypadku czcionki ma również wpływ na rozpoznanie tekstu w dokumencie.
Znaczące zacieśnienie tekstu to kolejny powód dla którego skuteczność procesu OCR może być dużo niższa.
Kolejną przyczyną dla którego wyniki rozpoznania tekstu przez program mogą być niższe, jest zbyt mały rozmiar czcionki. Minimalny rozmiar, w zależności od użytych w rozpoznaniu algorytmów, powinien się wahać pomiędzy 6 a 8 (W przypadku standardowej czcionki Times New Roman będzie to: 8 pkt dla x = 1,2 mm i 6 pkt dla x = 0,9 mm.)
ReCAPTCHA – największy program crowdsourcingu związany z OCR
Nawet najlepsze programy do OCR obecnie nie mają 100% skuteczności w procesie rozpoznania tekstu. Dlatego pozostaje zawsze mniejszy lub większy ułamek tekstu źle lub w ogóle nierozpoznanego. Ratunkiem jest tutaj oczywiście ręczne poprawienie przez człowieka tych błędów. W przypadku pojedynczych dokumentów o niewielkiej ilości stron nie stanowi to zbyt wielkiego problemu, kłopot zaczyna się w przypadku dokumentów składających się z dziesiątek, setek czy tysięcy stron. Aby tak tytaniczną pracę wykonać obecnie musiałby nad tym pracować sztab ludzi, którego wielkość byłaby uzależniona od wielkości księgozbioru. W przypadku bibliotek czy archiwów jest to nieopłacalne, przynajmniej w obecnej chwili.
Jednym z najciekawszych rozwiązań tego problemu jest mechanizm re-CAPTCHA, z którym na pewno wielu z nas spotkało się już w Internecie. Dzięki niemu miliony ludzi na świecie bierze udział w poprawianiu źle rozpoznanego tekstu, często nie zdając sobie z tego sprawy.

Projekt reCAPTCHA powstał na Uniwersytecie Carnegie-Mellona w Pittsburghu w celu digitalizacji książek i starych czasopism jak najmniejszym nakładem sił. Mechanizm działania tego projektu jest dość prosty. Użytkownik danej strony internetowej, by zakończyć np. rejestrację, musi przepisać dwa słowa podane przez program. Jedno ze słów ma charakter kontrolny (jest znane przez system), natomiast drugie, jest słowem nieprawidłowo rozpoznanym przez moduł OCR. Przy tym rozwiązaniu kolejność wyrazów jest losowa, natomiast ich jakość zbliżona. Użytkownik nigdy nie wie, które z nich jest zabezpieczeniem. Słowo trzykrotnie zweryfikowane przez różnych użytkowników jest przesyłane do źródła jako rozpoznane. W przypadku nie zadziałania mechanizmu w odniesieniu do trzech pierwszych użytkowników, problematyczne słowo jest prezentowane większej ilości osób. Decyzja o jego prawidłowym brzmieniu jest podejmowana na podstawie najczęściej pojawiających się odpowiedzi. Skuteczność tego rozwiązania wynosi 99,5%. ReCAPTCHA funkcjonuje od 2009 r., szacuje się że codziennie ok 200 milionów kodów zabezpieczających jest użytych przez internautów na całym świecie.
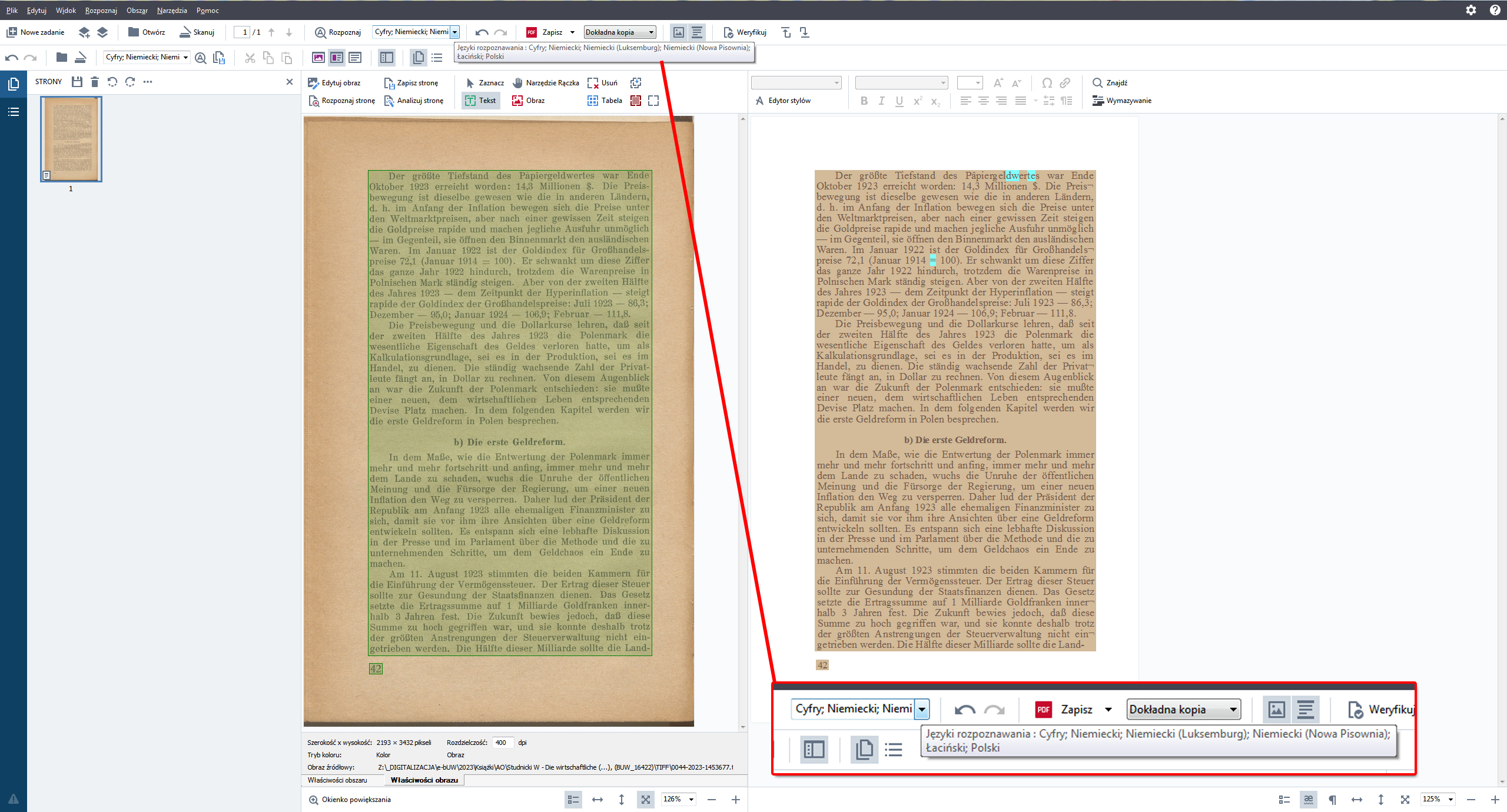
Proces OCR w bibliotece cyfrowej Crispa
W bibliotece cyfrowej Crispa tekst poddany procesowi OCR, możemy spotkać w dwóch typach plików.
Po pierwsze w plikach PDF. Pliki TIFF uzyskane w procesie skanowania poddawane są procesowi przetwarzania do formatu PDF oraz procesowi OCR.
Następnie za pomocą skryptów rozpoznany tekst, jest umieszczany w plikach ALTO. Pozwala to w przypadku plików tego rodzaju na połączenie OCR z plikami JPG. Wyszukując w bibliotece cyfrowej Crispa określony tekst, wyszukiwarka powinna nas przenieść do konkretnego pliku JPG, z którym plik ALTO został powiązał w pliku METS.
Do procesu OCR BUW stosuje program ABBY Fine Reader 15. Jest to jeden z najbardziej sprawdzonych i skutecznych programów stosowanych do rozpoznania tekstu.
W przypadku dosyć czytelnych i prostych tekstów znajdujących się w Crispie skuteczność ta waha się w granicach od 80% do 90%, co jest bardzo dobrym wynikiem jeśli chodzi o biblioteki cyfrowe. Taki poziom skuteczności rozpoznania tekstu umożliwia już w miarę dokładne przeszukiwanie pełnotekstowe w bibliotece cyfrowej oraz sprawne działanie czytników dla osób niewidzących i niedowidzących.
Adam Owczarczyk, Oddział Rozwoju Zasobów Elektronicznych