
Kelly Getz, Meryl Brodsky (Eds.) (2022). The Data Literacy Cookbook. Chicago: Association of College and Research Libraries
Publikacja dostępna w kolekcji e-książek UW.

To już druga recenzowana na łamach Bouvée bibliotekarska książka kucharska. Ponad dwa lata temu pisałam o przepisach na udaną komunikację naukową, dziś zajmę się (przy)gotowaniem danych.
Data literacy to termin oznaczający kompetencje w zakresie pracy z danymi. Praca z danymi to zdolność do czytania, rozumienia, tworzenia i przekazywania danych jako informacji.
Publikacja opracowana jest na wzór tradycyjnej książki kucharskiej – opisy poszczególnych lekcji przygotowane są jak przepisy, ze: składnikami, wartościami odżywczymi, alergenami, czasem przygotowania i opisem poszczególnych kroków. Jak piszą we wstępie redaktorki, „Nasi szefowie kuchni bardzo hojnie dzielili się swoimi planami lekcji, poradami i materiałami dydaktycznymi” (s. viii). Szefowie kuchni to kilkadziesiąt autorek i autorów z bibliotek w Australii, Kanadzie i Stanach Zjednoczonych.
Tradycyjnie książki kucharskie były opasłymi tomiskami, nie inaczej jest tutaj – dziewięć sekcji, 65 rozdziałów, 256 stron przepisów na data literacy pod różnymi postaciami. Na potrzeby tego wpisu wybrałam najlepsze kąski, które, mam nadzieję, zaostrzą apetyt osób czytających i zachęcą do samodzielnego zajrzenia do recenzowanego e-booka. Warto podkreślić, że materiały (przepisy) w nim zawarte udostępnione są na licencjach Creative Commons, co znacznie ułatwia szerokie wykorzystanie.
Poniżej przedstawiam tematykę poszczególnych sekcji książki:
Sekcja 1 – Interpretacja sondaży i ankiet (3 rozdziały)
Sekcja 2 – Wyszukiwanie i ocena danych (11 rozdziałów)
Sekcja 3 – Manipulacja i przekształcanie danych (5 rozdziałów)
Sekcja 4 – Wizualizacja danych (12 rozdziałów)
Sekcja 5 – Zarządzanie danymi i ich udostępnianie (6 rozdziałów)
Sekcja 6 – Dane geoprzestrzenne (5 rozdziałów)
Sekcja 7 – Dane w różnych dyscyplinach badawczych (9 rozdziałów)
Sekcja 8 – Data literacy – działania informacyjne i zaangażowanie (8 rozdziałów)
Sekcja 9 – Programy nauczania dotyczące kompetencji korzystania z danych (6 rozdziałów)
Warto zacząć od podstawowych pojęć i scharakteryzowania różnych typów danych. Takie informacje można znaleźć w rozdziale 4. (Three-Step Data Searching), w poręcznym handoucie przygotowanym przez autorkę z Uniwersytetu Kalifornijskiego w San Diego.
DATA—DEFINED
da·ta noun plural but singular or plural in construction, often attributive \ˈdā-tə, ˈda- also ˈdä-\
1. factual information (as measurements or statistics) used as a basis for reasoning, discussion, or calculation
2. information output by a sensing device or organ that includes both useful and irrelevant or redundant information and must be processed to be meaningful
3. information in numerical form that can be digitally transmitted or processed
(From Merriam-Webster, http://www.merriam-webster.com/dictionary/data)TYPES OF DATA
Observational: Captured in real-time, typically outside the lab
Examples: Sensor readings, survey results, images, audio, video
Experimental: Typically generated in the lab or under controlled conditions
Examples: test results
Simulation: Machine generated from test models
Examples: climate models, economic models
Derived / Compiled: Generated from existing datasets
Examples: text and data mining, compiled database, 3D modelsCOMMON FORMATS
Text: field or laboratory notes, survey responses
Numeric: tables, counts, measurements
Audiovisual: images, sound recordings, video
Models, computer code, geospatial data
Discipline-specific: FITS in astronomy, CIF in chemistry
Instrument-specific: equipment outputsKEY TERMS
Źródło: Getts & Brodsky (red.), 2022, s. 19.
Microdata: Data directly observed or collected from a specific unit of observation
Examples
Census: the unit of observation is probably an individual, a household, or a family
Survey or poll: the responses of a single respondent
Aggregate Data: Is higher-level data that have been compiled from smaller units of data
Examples: inflation rate, consumer price index, demographic data for city or state
Statistics: Numerical data that has been organized and interpreted, usually displayed in tables
Datasets: A dataset or study is made up of the raw data file and any related files, usually the codebook and setup files.
Most datasets require at least basic statistical analysis (Stata, SPSS, R, etc.) or spreadsheet programs (Excel) to use.
Repositories: A data repository is a collection of datasets that have been deposited for storage and findability.
– They are often discipline specific and/or affiliated with a re- search institution
Examples: ICPSR, Harvard Dataverse Network, UC San Diego Digital Collections
Zatrzymałam się też dłużej na rozdziale 32. (Making File Names for Digital Exhibits), który autorki z Uniwersytetu w Oregonie poświęciły prawidłowemu nazewnictwu plików. Jak stworzyć konwencję nazewnictwa plików, która jest czytelna dla człowieka i maszyny? Jak stworzyć standard nazewnictwa plików, który może być interpretowany i reprezentowany w ramach przepływu pracy związanego z całym projektem? Ten rozdział pokazuje, w jaki sposób konwencja nazewnictwa plików wspiera tworzenie dokumentacji projektu. Warto do niego zajrzeć, nawet jeśli wydaje się nam, że potrafimy nadawać nazwy plikom. Jak ważne jest to zagadnienie, niech świadczy fakt, że każdy plan zarządzania danymi powinien mieć sekcję dotyczącą właśnie konwencji nazewnictwa plików.
A skoro o planie zarządzania danymi mowa, to ciekawy jest także rozdział 33. (Data Management Plans Failures. Teaching the Importance of DMPs through Cautionary Examples). DMP, czyli data management plan, to obowiązkowy element każdego projektu badawczego. Niestety nadal część środowiska badaczy traktuje sporządzenie planu właśnie jako przykry obowiązek pozamerytoryczny, a nie jako integralną część badań, od której wiele zależy. Dlatego rozdział pokazujący, jakimi konsekwencjami skutkuje nieprawidłowo przygotowany plan zarządzania danymi jest bardzo pouczający i powinien być lekturą obowiązkową dla wszystkich osób nastawionych sceptycznie do tej części wniosku badawczego. W rozdziale przedstawiono konkretne przykłady, a każdy z nich pokazuje dobrze zorganizowany, duży projekt, w którym nie wzięto pod uwagę długoterminowego wykorzystania danych i dostępu do nich, przez co po jego zakończeniu użytkownicy nie mogą z niego korzystać.
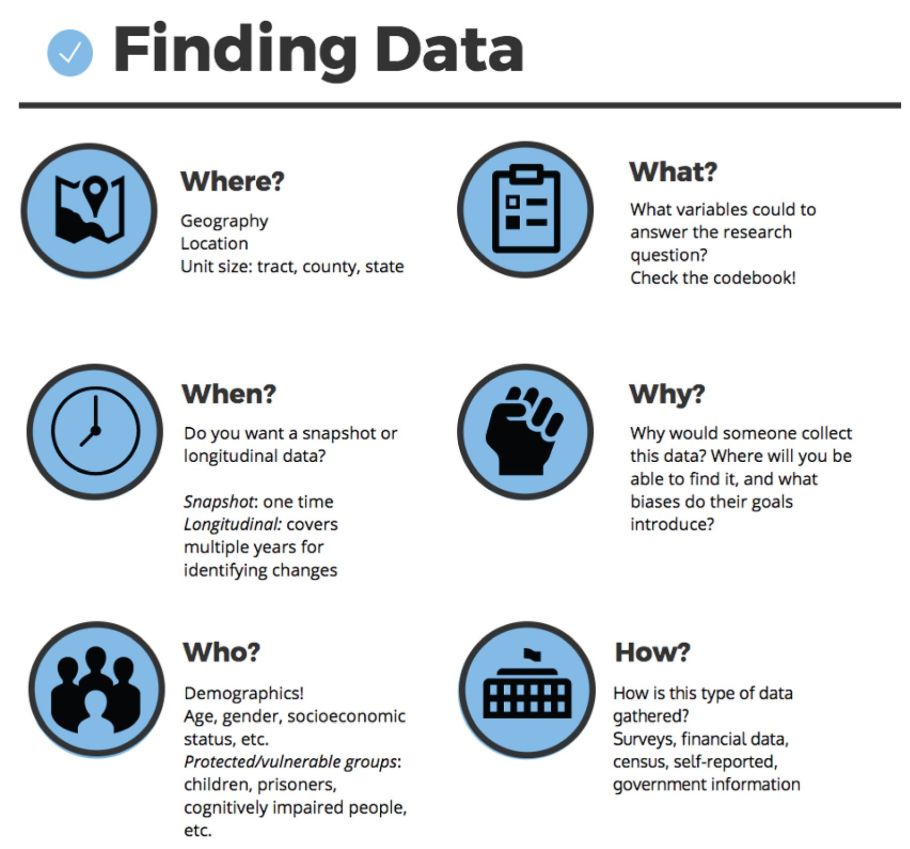
Prawidłowe zarządzanie danymi badawczymi jest istotne w każdej dyscyplinie, ponieważ dane wytwarzane są podczas wszystkich badań. Sekcja 7. książki poświęcona jest właśnie różnym dyscyplinom i danym w nich. Omówiono: humanistykę cyfrową, dane dotyczące bioróżnorodności, nauki ścisłe, nauki społeczne, dane finansowe, analizę danych biznesowych oraz dane marketingowe. Rozdział 50., z którego pochodzi poniższa grafika, poświęcony jest wyszukiwaniu danych dla nauk społecznych.
Ostatnim z kąsków z recenzowanej książki, który chciałam zaprezentować na łamach bloga, jest rozdział 60. (Cooking Up a Data Literacy Course) znajdujący się w Sekcji 9. książki. To naprawdę długi przepis na piętnastotygodniowy kurs kształtujący kompetencję zarządzania danymi. Warto spojrzeć na jego proponowaną zawartość, aby sprawdzić, w których zagadnieniach osiągnęło się biegłość (lub przynajmniej sporą wiedzę teoretyczną), a które warto podszlifować, poćwiczyć czy o nich doczytać. Właśnie na takie samodouczanie szczerze namawiam.
Zuza Wiorogórska, Pełnomocniczka ds. edukacji informacyjnej i komunikacji naukowej
